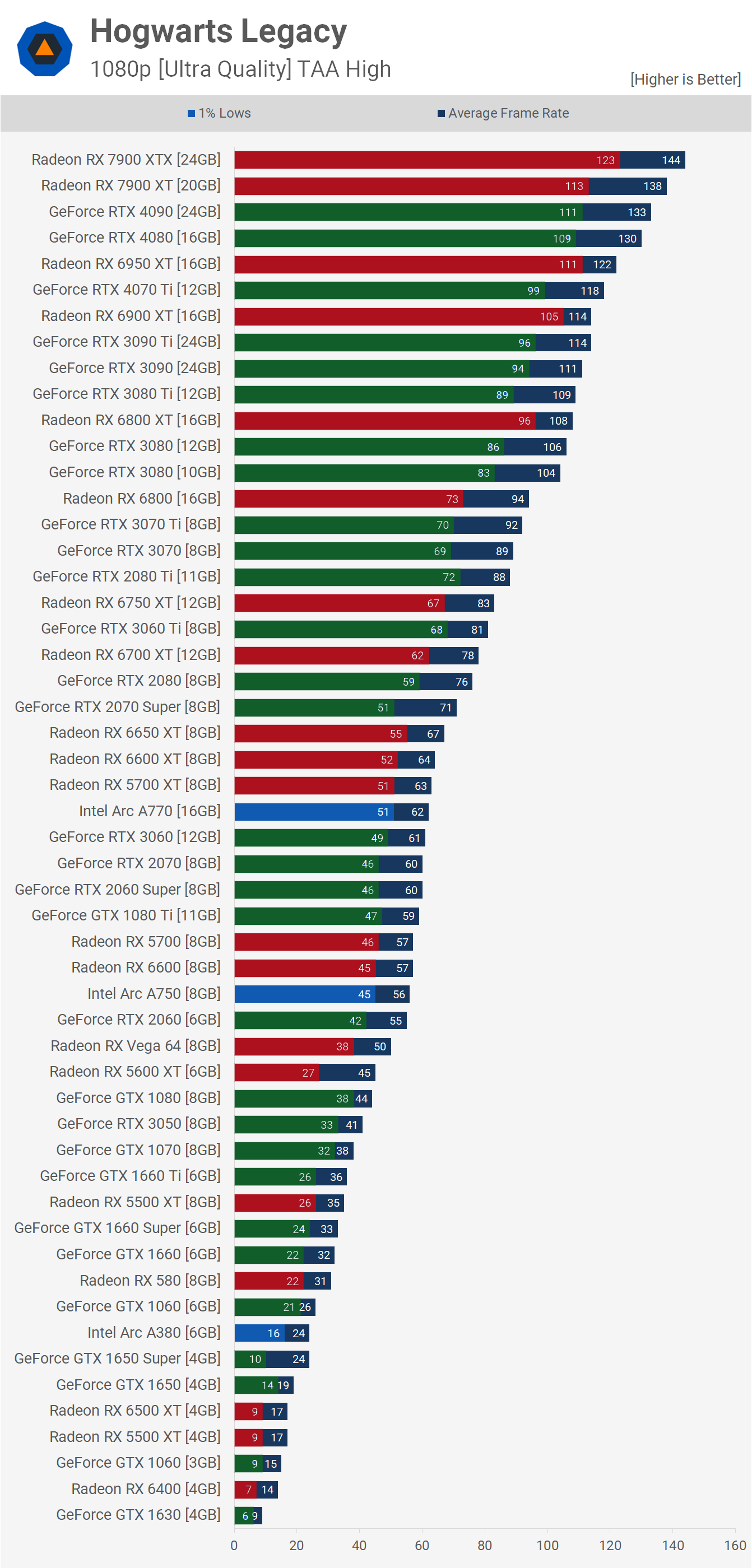
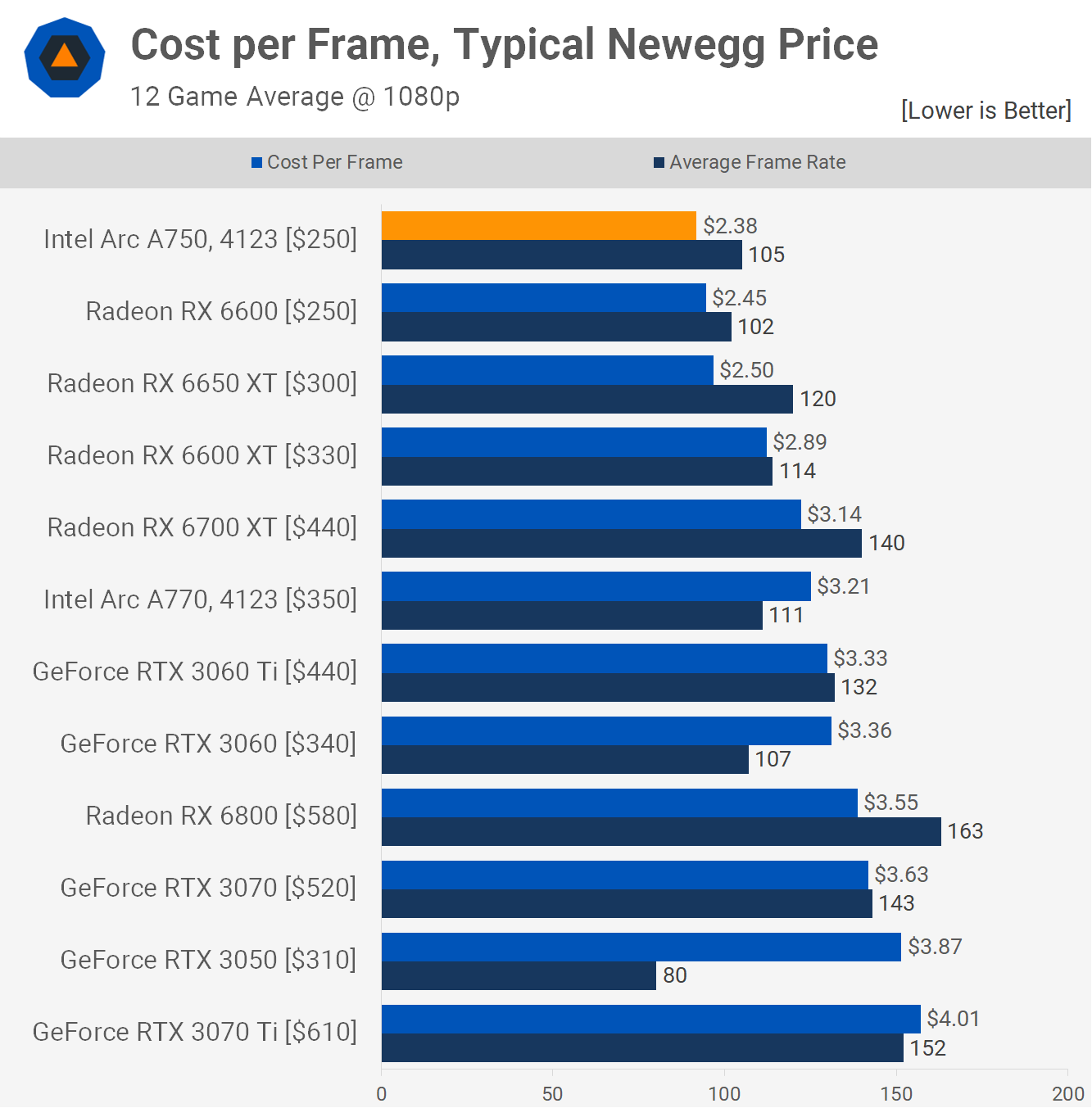
Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave (Part 1)
Por um escritor misterioso
Descrição

Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave (Part 1)

MLPerf Training 3.0 Showcases LLM; Nvidia Dominates, Intel/Habana Also Impress
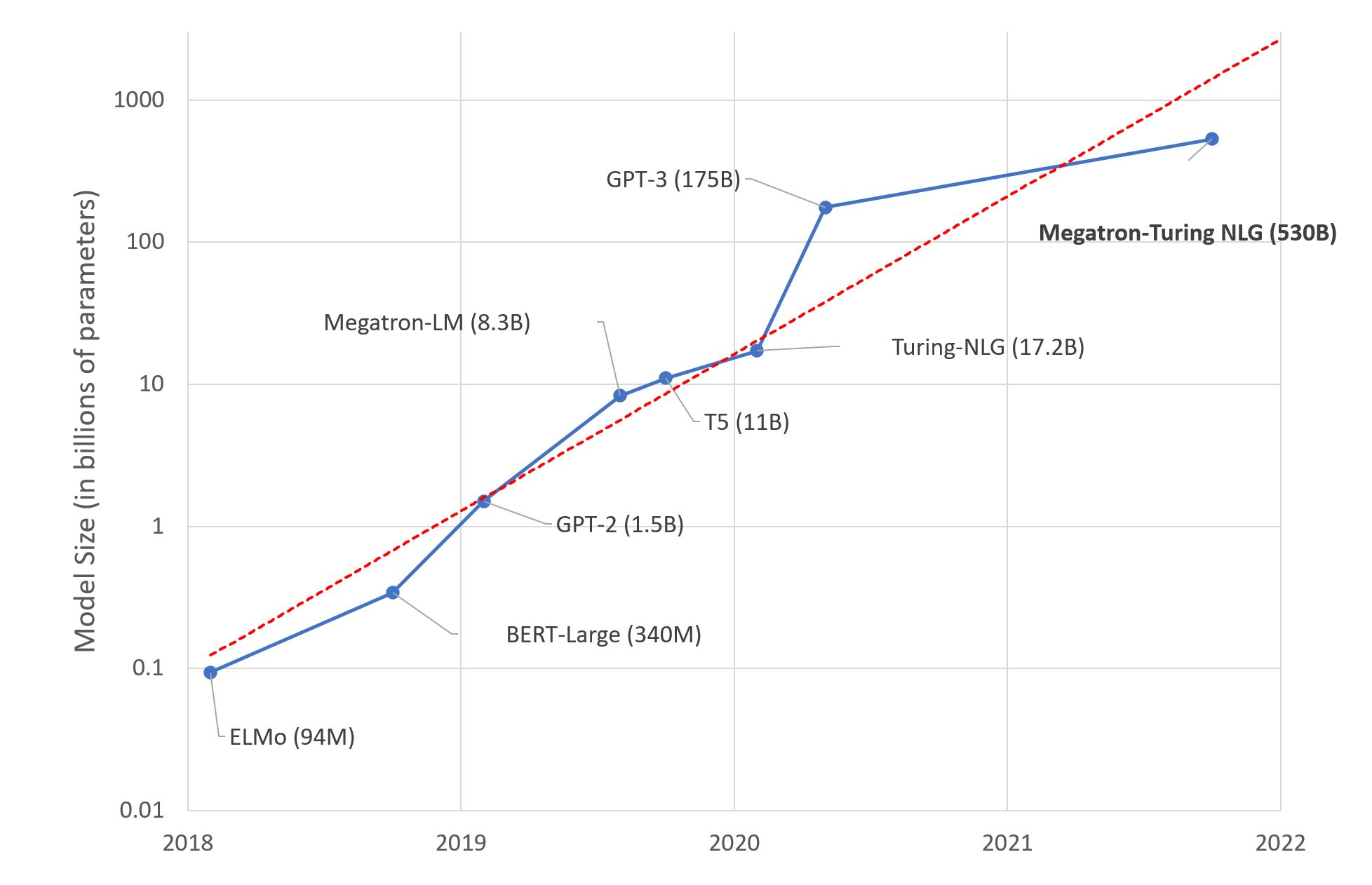
High-Performance LLM Training at 1000 GPU Scale With Alpa & Ray

The $1 Billion And Higher Ante To Play The AI Game - The Next Platform
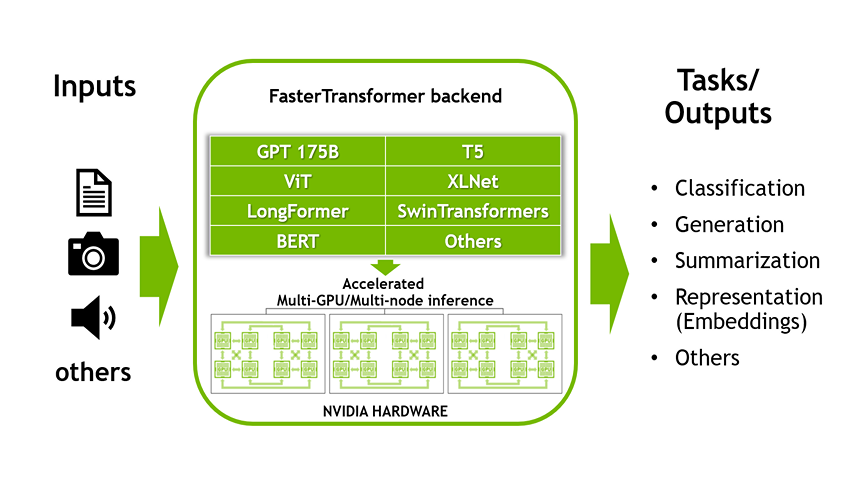
Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server
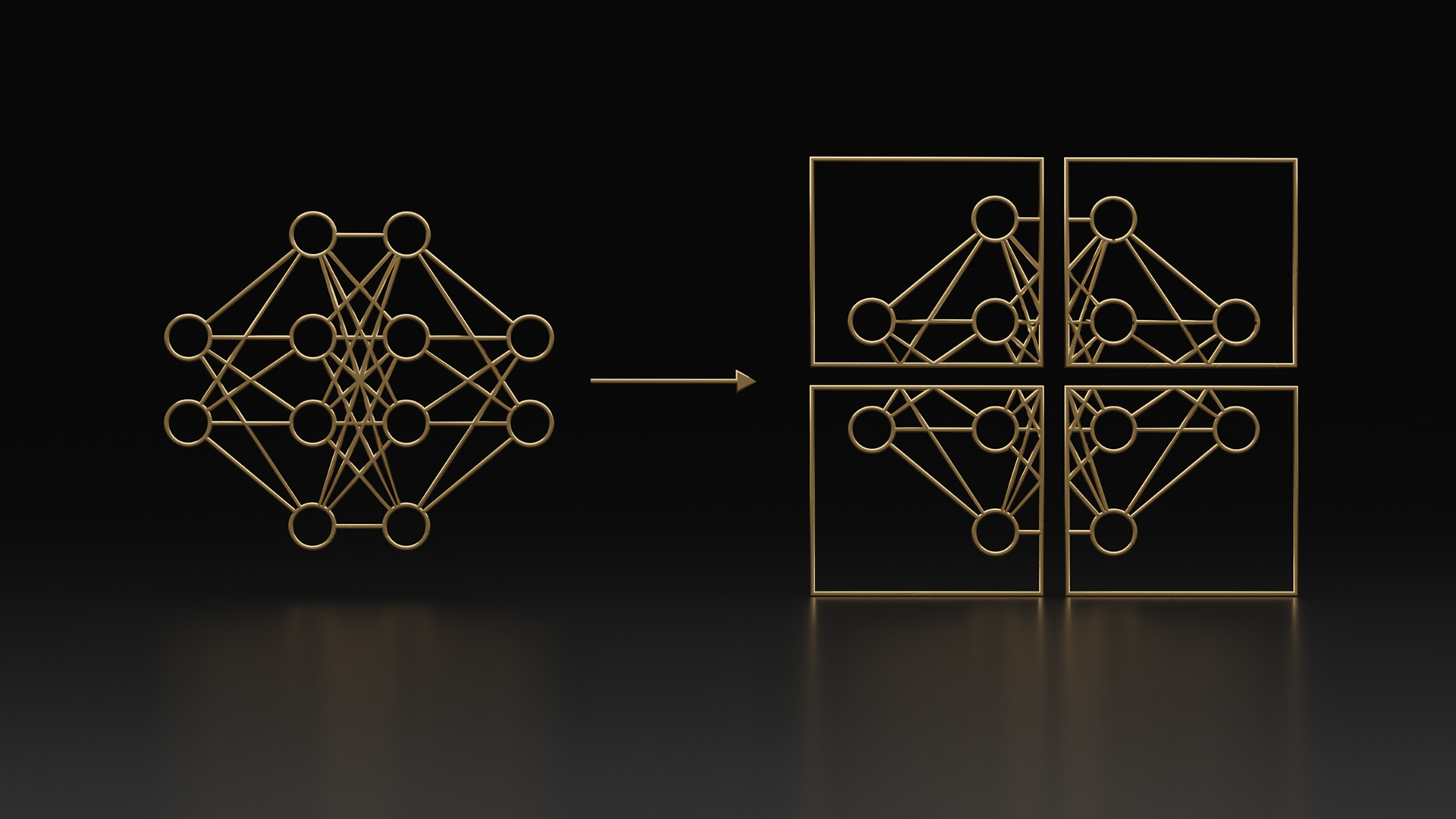
Deploying a 1.3B GPT-3 Model with NVIDIA NeMo Framework

Hagay Lupesko on LinkedIn: Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave…

Navigating the future of GPU accelerated innovation., by Amulya Sharma, Nov, 2023

Nvidia Leads, Habana Challenges on MLPerf GPT-3 Benchmark - EE Times

NVIDIA H100 Tensor Core GPU - Deep Learning Performance Analysis

Nvidia sweeps AI benchmarks, but Intel brings meaningful competition

J.Vikranth Jeyakumar on LinkedIn: GitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an…

Nvidia H100 GPUs set time to beat in MLPerf generative AI benchmark debut – Jon Peddie Research
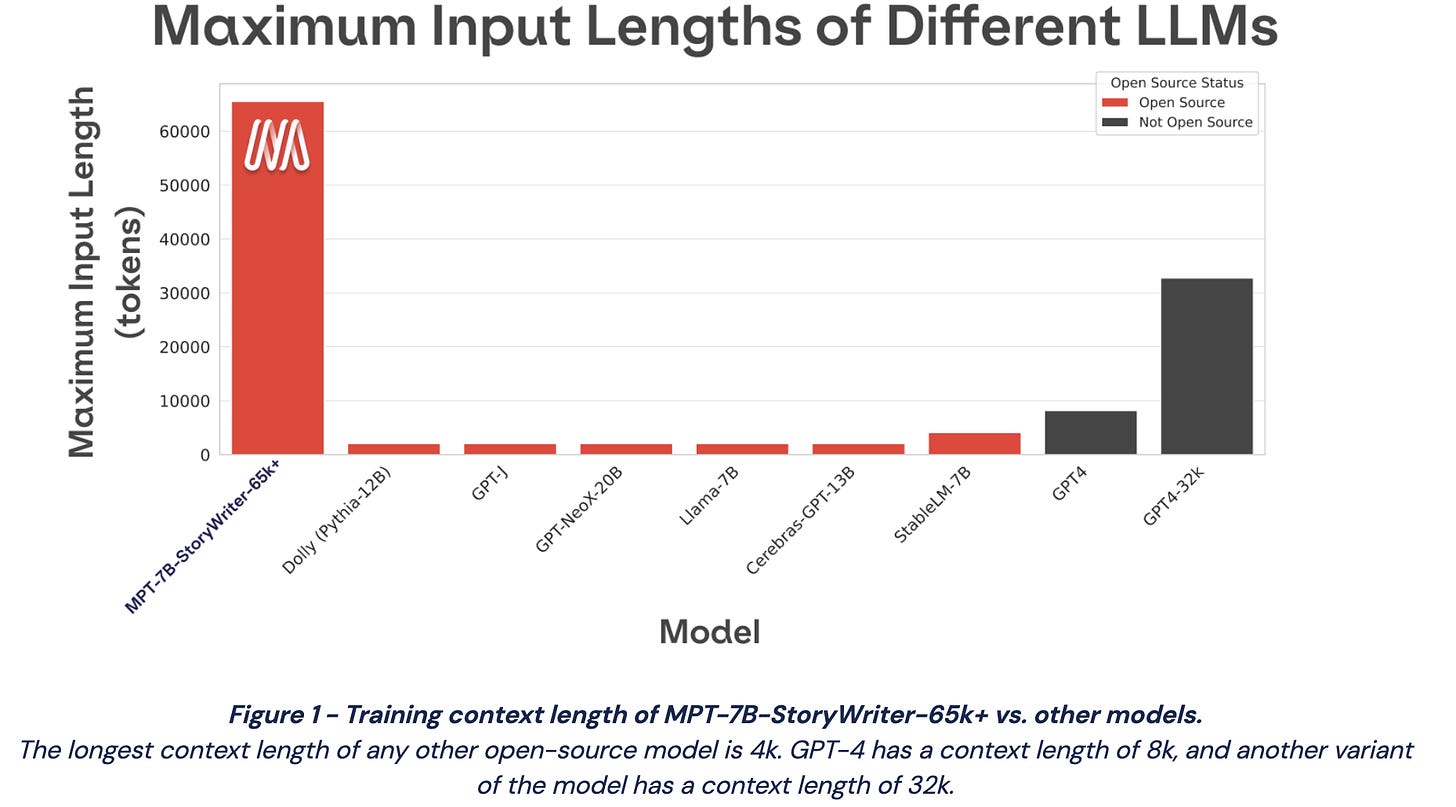
2023-5-7 arXiv roundup: Easy loss spike fix, LLongboi, H100s, stable diffusion for $50k

NVIDIA H100 Tensor Core GPU Dominates MLPerf v3.0 Benchmark Results
de
por adulto (o preço varia de acordo com o tamanho do grupo)