Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Descrição
DeepMind's new AI is worthy successor to the first program to beat a human at Go.

Alphazero :: Computer-bridge1
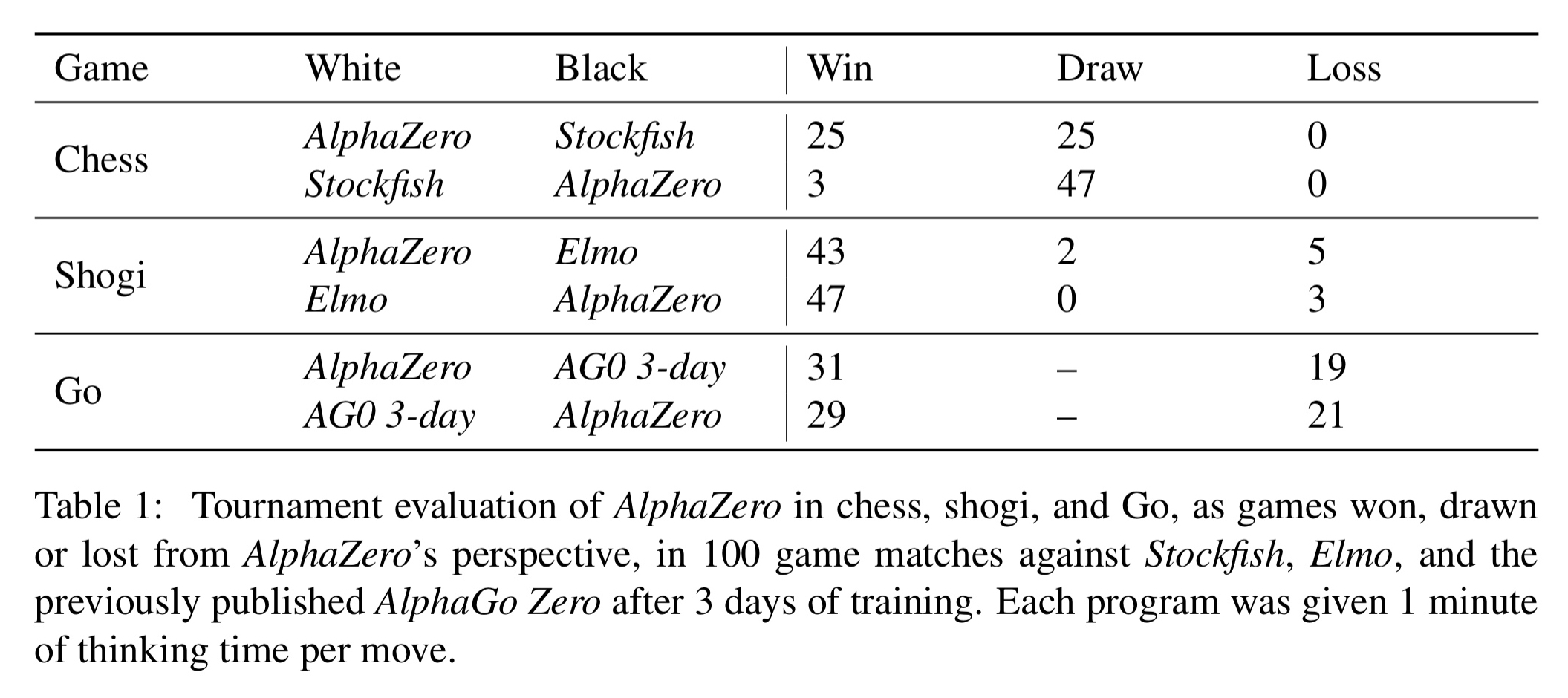
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
Will AlphaZero become smarter and smarter forever, if it plays chess against itself for unlimited times? - Quora

Simple Alpha Zero

Game Changer: AlphaZero's Groundbreaking by Sadler, Matthew

dThe 3 Tricks That Made AlphaGo Zero Work, by Seth Weidman, HackerNoon.com

Checkmate: how we mastered the AlphaZero cover, Science

It's able to create knowledge itself': Google unveils AI that learns on its own, Science

MCTS in AlphaGo Zero a, Each simulation traverses the tree by selecting

How the Artificial Intelligence Program AlphaZero Mastered Its Games

How Does AlphaZero Play Chess?

Artificial Intelligence Learns to Learn Entirely on Its Own

DeepMind's AI beats world's best Go player in latest face-off
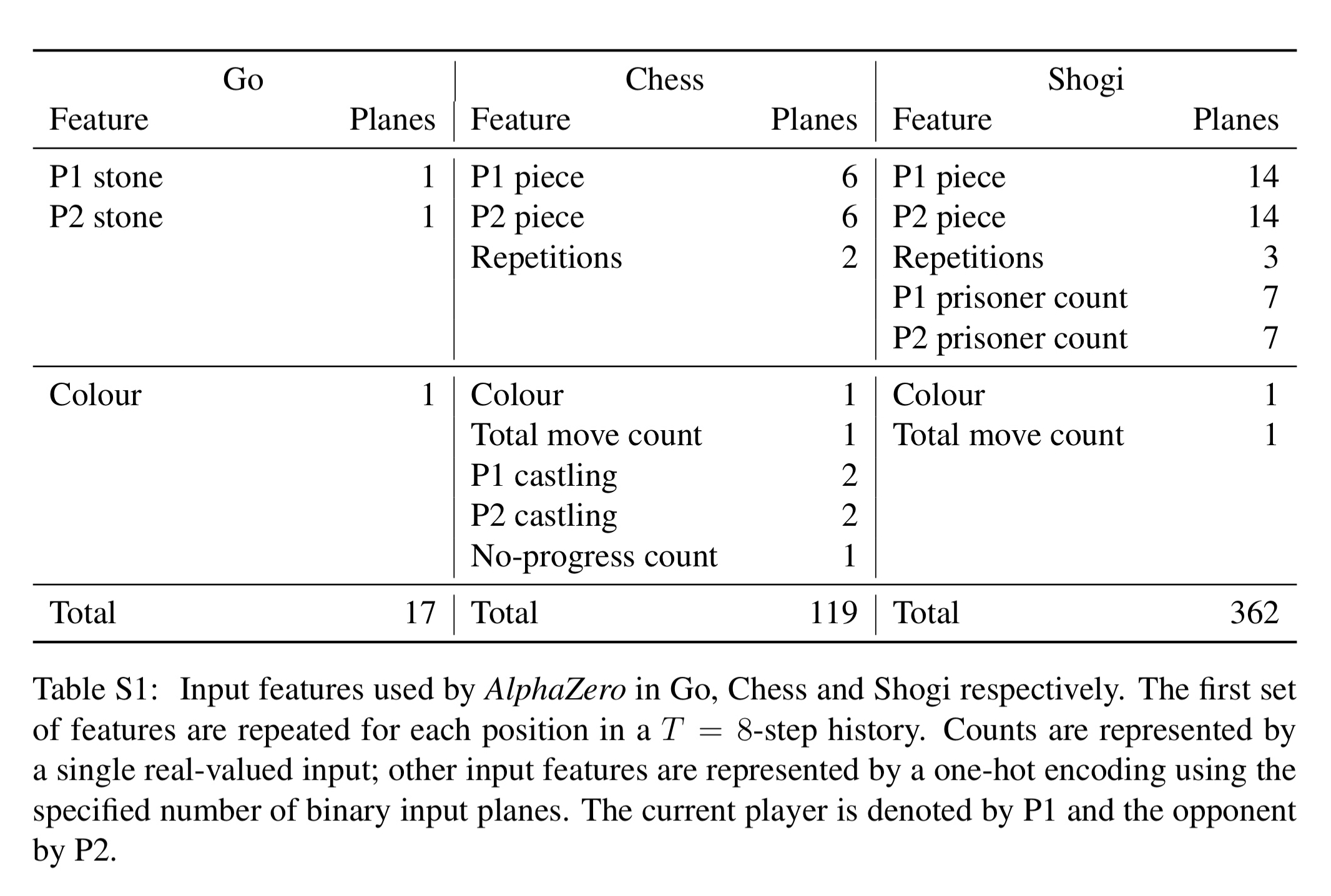
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
de
por adulto (o preço varia de acordo com o tamanho do grupo)